Hypothesis Testing
Hypothesis testing is a major paradigm in statistics. It is closely
linked with the computation of specified probability distribution
functions. The basic notion is simple. We obtain a sample value v of
a random variable T and we ask how probable it is that the sample
value v would appear under a hypothesis H which makes the distribution
of T well-defined. If the probability that, under the hypothesis H, v
or a more extreme value of T appears is small, we take this as
evidence that the hypothesis H is unlikely to be true. In other
words, we conclude that the test of the hypothesis H has not supported
H.
The random variable T is called the test statistic. If many samples
of various random variables are taken, they are often combined in
some, possibly quite elaborate, manner to obtain a single sample of a
derived test statistic T. In other cases, the test statistic may be a
vector-valued random variable with a multivariate distribution
function. For example, the test statistic associated with the
famous t-test for testing
the hypothesis that two normally-distributed random variables have
the same mean is
the difference between the means, or variance-adjusted means, of
two sets of sample values corresponding to
the two random variables being studied.
In order to compute the probability p that, under the hypothesis
H, the sample value v or a more extreme value of T appears, we
must be able to compute P(T ≤ v | H), which is the distribution
of the test statistic T under the hypothesis H. We shall denote a
random variable with this distribution by TH. The hypothesis H
must be such that the distribution function of TH is known; this
means that H is often of the form: "there is no difference between
two sets of samples'', since it is generally easier to deduce the
distribution of TH in this case. Thus, H is called the null
hypothesis, meaning the "no difference'' hypothesis.
Suppose that the distribution function of TH is G(x) : = P(TH Ł
x).
Also suppose that the density function dG(x)/dx is a unimodal
"bell-shaped'' curve, so that the extreme sample values of TH lie
toward +Ą
and -
Ą
. Suppose the value v is given as a
sample value of T. We may compute, for example, p = P(|
TH -
E(TH)|
ł
|
v-
E(TH)|
).
This is a particular form of a so-called two-tailed test. p is the
probability that the value v or a "more extreme'' value occurs as a
sample value of T, given H. If p is sufficiently small, we may
reject the null hypothesis H as implausible in the face of the "evidence'' v. We call such a probability p the
plausibility probability of H, given v.
If the test statistic TH were known to be non-negative and the density
function dG(x)/dx were a function, such as the exponential density
function, which decreases on [0,Ą
), then we might use a so-called
one-tail test, where we compute the probability p = P(TH ł
v).
In general, we may specify a particular value a
as our
criterion of "sufficiently small'' and we may choose any subset S
of the range of T such that P(TH Ď
S) = a
. Then if v Ď
S, the null hypothesis H may be judged implausible. S is
called the acceptance set, because, when v Î
S, the null
hypothesis H is not rejected. The value a
= P(TH Ď
S)
is the probability that we make a mistake if we reject H when v Ď
S.
How should the acceptance set S be chosen? S should be chosen to
minimize the chance of making the mistake of accepting H when H
is, in fact, false. But, this can only be done rigorously with
respect to an alternative hypothesis Ha such that the distribution
of T given Ha is known. We must postulate that H and Ha are
the only non-negligable possibilities. Sometimes, Ha = \lnot H is
a suitable alternate hypothesis, but more often, this is not suitable.
Given Ha, the probability we falsely accept H when the alternate
hypothesis Ha is true is P(THa
∉
S) = : b
, and we can
choose S such that P(TH
∉
S) = a
while P(THa
∈
S) = b is minimized.
The value P(THa Ď
S) = 1-
b
is called the power of
the test of the null hypothesis H versus the alternate hypothesis
Ha. Choosing S to minimize b
is the same as choosing S
to maximize the power 1-
b
.
If we don't care about achieving the optimal power of the test with
respect to a specific alternate hypothesis, but merely wish to compute
the plausibility probability that v or a more extreme sample value of
T would occur given H, in a fair manner, then we may proceed as
follows.
Let m = median(TH); thus, P(TH ł
m) = 0.5. Now, if v < m,
choose r1 = v and r2 as the value such that P(m < TH < r2) = P(v < TH < m), otherwise choose r2 = v and choose r1 as the
value such that P(r1 < TH < m) = P(m < TH < v). Then the
two-tail plausibility probability a
= 1-
P(r1 < TH < r2). If
v < m, a
= 2P(TH Ł
v), otherwise, if v ł
m, a
= 2(1-
P(TH Ł
v)).
If we know that the only values more extreme than v which we wish to
consider as possible are those in the same tail of the density
function that v lies in, then we may compute the one-tail
plausibility probability as a
= P(TH Ł
v) if v Ł
m and
a
= P(TH ł
v) if v > m.
Consider testing the null hypothesis H versus the alternate hypothesis
Ha using a sample value v of the test random variable T with the
acceptance set S. We have the following outcomes.
v Î
S
v Ď
S
accept H
reject H
H
prob 1-a
prob a
correct
rejection error
accept
H
reject H
Ha
prob b
prob 1-b
acceptance error correct
|
|
| | |
P(TH Ď
S) = P(we falsely reject H | H) |
| |
| | |
P(TH Î
S) = P(we correctly accept H | H) |
| |
| | |
P(THa Î
S) = P(we falsely accept H | Ha) |
| |
| | |
P(THa Ď
S) = P(we correctly reject H | Ha) |
| |
|
|
|
Let Q be the sample-space of the test statistic T.
We assumed above that either H(q)=1 for all q Î
Q
or H(q)=0 for all q Î
Q, but this universal applicability
of H or Ha may be relaxed.
Suppose the hypothesis
H and the alternate hypothesis Ha may each hold at different points of
Q, so that H and Ha define corresponding complementary
Bernouilli random variables on Q. Thus H(q)=1 if H holds at
the sample point q Î
Q and H(q)=0 if H does not hold at the sample
point q; Ha is defined on Q in the same manner.
Let P({q Î
Q | H(q) = 1}) be denoted by P(H) and
let P({q Î
Q | Ha(q) = 1}) be denoted by P(Ha).
P(H) is called the incidence probability of H
and P(Ha) is called the incidence probability of Ha.
As before, we postulate
that P(H)=1-
P(Ha). Often P(H) is 0 or 1 as we assumed above,
but it may be
that 0 < P(H) < 1. In this latter case, our test of hypothesis
can be taken as a test of whether H(q)=1 or Ha(q)=1
for the particular sample point q at hand for which
T(q)=v; the test statistic value v may be taken as evidence
serving to increase or diminish the probability of H(q)=1.
Note that we cannot compute the "posterior'' probability that H(q)=1 (and
that Ha(q)=0), or conversely, unless we have
the "prior'' incidence probability of H being true in the
sample-space Q. In particular,
if we assume the underlying sample-space point q is chosen at
random, then:
If we take the occurrence of H(q)=0 as being a determination of a "positive state'' of the random sample-space point q, then
(1-
a
)P(H) is the probability of a true negative sample,
a
P(H) is the probability of a false positive sample,
b
(1-
P(H)) is the probability of a false negative sample,
and (1-
b
)(1-
P(H)) is the probability of a true positive sample.
Now let us look at a particular case of an hypothesis test, namely the
so-called F-test for equal variances of two normal populations.
Suppose X11, X12, ..., X1n1 are independent
identically-distributed random variables distributed as
N(m
1,s
12), and X21, X22, ..., X2n2 are
independent identically-distributed random variables distributed as
N(m
2,s
22). The corresponding sample-variance random
variables are
|
S12= |
n1
ĺ
j=1
|
(Xij-
|
-
X
|
1
|
)2/(n1-
1) and S22= |
n2
ĺ
j=1
|
(X2j-
|
-
X
|
2
|
)2/(n2-
1), |
|
where [`
X]1=ĺ
j=1n1X1j/n1 and
[`
X]2=ĺ
j=1n2X2j/n2.
Let R denote the sample variance ratio S12/S22. Then R ~
(s
12/s
22)Fn1-
1,n2-
1, where Fn1-
1,n2-
1 is a
random variable having the F-distribution with (n1-
1,n2-
1)
degrees of freedom.
We take the null hypothesis H to be s
1/s
2 = 1, so
that, given H, the test statistic R is known to be distributed as
Fn1-
1,n2-
1. In order to determine the acceptance region S
with maximal power for a
fixed, we take the alternate
hypothesis Ha to be s
1/s
2 = a. Then S is the
interval [r1,r2] where P(r1/a2 Ł
Fn1-
1,n2-
1 Ł
r2/a2) = b
is minimal, subject to 1-
P(r1 Ł
Fn1-
1,n2-
1 Ł
r2) = a
.
Let G(z) = P(Fn1-
1,n2-
1 Ł
z), the distribution function of
Fn1-
1,n2-
1, and let g(z) = G˘
(z), the probability density
function of Fn1-
1,n2-
1. Then, we have r1 = rootz[g(z)g(h(z)/a2)-
g(h(z)) g(z/a2)] and r2 = h(r1), where h(z) = G-
1(1-
a
+G(z)).
A simplified, slightly less powerful, way to choose the acceptance
region S is to take S = [r1,r2] where r1 is the value such
that P(Fn1-
1,n2-
1 Ł
r1) = a
/2 and r2 is the value
such that P(Fn1-
1,n2-
1 ł
r2) = a
/2. Another way to
select the acceptance region is to take S = [1/r,r], where r is
the value such that P(1/r Ł
Fn1-
1,n2-
1 Ł
r) = 1-
a
.
When n1 = n2, the acceptance region [r1, r2] and the
acceptance region [1/r, r] are identical.
The foregoing clearly exemplifies the fact that there is a trade-off
among the acceptance error probability b
, the rejection error
probability a
, and the sample sizes (n1,n2). If we wish to have
a smaller a
, then we must have a greater b
or greater values of
n1 and n2. Similarly, b
can only be reduced if we allow a
or n1 and n2 to increase. In general, given any two of the test
parameters a
, b
, or (n1,n2), we can attempt to determine the
third, although a compatible value need not exist. Actually, in most
cases, a fourth variable representing the distinction between the null
hypothesis and the alternate hypothesis, such as the value a above,
enters the trade-off balancing relations.
For the simplified two-tailed F-test with S = [r1, r2], the relations
among a
, b
, a, n1, n2, r1, and r2 are listed below.
P(Fn1-
1,n2-
1 Ł
r1) = a
/2,
P(Fn1-
1,n2-
1 ł
r2) =
a
/2,
P(r1 Ł
a2Fn1-
1,n2-
1 Ł
r2) = b
.
For the alternate case with S = [1/r, r], the relations among a
, b
, a,
n1, n2, and r are:
P(1/r Ł
Fn1-
1,n2-
1 Ł
r) = 1-a
P(1/r Ł
a2Fn1-
1,n2-
1 Ł
r) = b
.
In order to reduce the number of unknowns, we may postulate that n1
and n2 are related as n2 = q
n1, where q
is a fixed
constant.
The value of b
is determined above by the distribution of
a2Fn1-
1,n2-
1, because for the F-test, the test statistic,
assuming the alternate hypothesis s
1/s
2 = a, is the
random variable a2Fn1-
1,n2-
1 whose distribution function is
just the F-distribution with the argument scaled by 1/a2. In
other cases, the distribution of the alternate hypothesis test
statistic THa is more difficult to obtain.
If we take the dichotomy s
1/s
2 = 1 vs. s
1/s
2 = a as the only two possibilities, then a
one-tailed F-test is most appropriate. Suppose a > 1. Then we
take S = [-
Ą
,r2], and we have the relations:
P(Fn1-
1,n2-
1 ł
r2) = a
, and P(a2Fn1-
1,n2-
1 Ł
r2) = b
. If a < 1, then with the null hypothesis
s
1/s
2 = 1 and the alternate hypothesis
s
1/s
2 = a, we should take S = [r1,Ą
]. Then,
P(Fn1-
1,n2-
1 Ł
r1) = a, and P(a2Fn1-
1,n2-
1 ł
r1) = b
.
Generally, hypothesis testing is most useful when a decision is to be
made. Instead, for example, suppose we are interested in the variance
ratio (s
1/s
2)2 between two normal populations for
computational purposes. Then it is preferable to use estimation
techniques and confidence intervals to characterize
(s
1/s
2), rather than to use a hypothesis test whose only
useful outcome is "significantly implausible'', or "not
significantly implausible'' with the significance level a
(which is the same as the rejection error probability).
Let r1 satisfy P(Fn1-
1,n2-
1 Ł
r1) = a
1, and let
r2 satisfy P(Fn1-
1,n2-
1 Ł
r2) = 1-
a
2, with
a
1+a
2 = a
< 1. Then P((s
1/s
2)2r1 > R
or R > (s
1/s
2)2r2) = a
1+a
2, and
P((s
1/s
2)2r1 < R and R < (s
1/s
2)2r2) = 1-
a
1-
a
2 = P((s
1/s
2)2 < R/r1 and R/r2 < (s
1/s
2)2) = P(R/r2 < (s
1/s
2)2 < R/r1).
Thus, [R/r2, R/r1] is a (1-
a
)-confidence interval
which is an interval-valued random variable that contains the true
value (s
1/s
2) with probability 1-
a
. The length
of this interval is minimized for n2 > 2 by choosing a
1 and
a
2, subject to a
1+a
2 = a
, such that
G-
1(a
1)2g(G-
1(1-
a
2))-
G-
1(1-
a
2)2g(G-
1(a
1)) = 0, where G(x) = P(Fn1-
1,n2-
1 Ł
x) and where g(x) = G˘
(x),
the probability density function of Fn1-
1,n2-
1. Then a
1 = rootz(G-
1(z)2g(G-
1(1+a
-
z))-
G-
1(1-
a
+z)2g(G-
1(z)),
and a
2 = a
-
a
1, r1 = G-
1(a
1), and r2 = G-
1(1-
a
2).
Let v denote the observed sample value of R. Then [v/r2,v/r1] is a sample (1-
a
)-confidence interval for
(s
1/s
2)2.
The MLAB mathematical and statistical modeling system contains
functions for various statistical tests and also functions to compute
associated power and sample-size values. Let us consider an example
focusing on the simplified F-test discussed above. We are given the
following data:
x1: -1.66, 0.46, 0.15, 0.52, 0.82, -0.58, -0.44, -0.53,
0.4, -1.1
x2: 3.02, 2.88, 0.98, 2.01, 3.06, 2.95, 3.4, 2.76, 3.92, 5.02, 4, 4.89,
2.64, 3.08
We may read this data into two vectors in MLAB and test whether the
two data sets x1 and x2 have equal variances by using the MLAB
F-test function /QFT/, which implements the [1/r,r] simplified
F-test specified above. The MLAB dialog to do this is exhibited
below
*x1 = read(x1file); x2 = read(x2file);
*qft(x1,x2)
[F-test: are the variances v1 and v2 of 2 normal populations
plausibly equal?]
null hypothesis H0: v1/v2 = 1. Then v1/v2 is F-distributed with
(n1-1,n2-1) degrees of freedom. n1
n2 are the sample sizes.
The sample value of v1/v2 = 0.577562, n1 = 10, n2 = 15
The probability P(F < 0.577562) = 0.205421
This means that a value of v1/v2 smaller than 0.577562 arises about
20.542096 percent of the time, given H0.
The probability P(F > 0.577562) = 0.794579
This means that a value of v1/v2 larger than 0.577562 arises about
79.457904 percent of the time, given H0.
The probability: 1-P(0.577562 < F < 1.731416) = 0.377689
This means that a value of v1/v2 more extreme than 0.577562 arises
about 37.768896 percent of the time, given H0.
The a
= .05 simplified F-test acceptance set of the form
[1/r, r] can be computed directly as follows. /QFF/ is the name of
the F-distribution function in MLAB.
* n1 = nrows(x1)-1; n2 = nrows(x2)-1;
* fct rv(a) = root(z,.001,300,qff(1/z,n1,n2)+1-qff(z,n1,n2)-a)
* r = rv(.05)
* type 1/r,r
= .285471776
R = 3.50297326
Thus, a sample of F9,14 will lie in [.2855,3.503] with probability
.95.
The rejection error probability b
can be plotted as a function of
the acceptance error probability a
for the sample sizes 10 and 15 by
using the builtin function /QFB/ as follows. The function
/QFB/(a
,n,q
,e) returns the rejection error probability value
b
that corresponds to the sample sizes n and q
n, with
the acceptance error probability a
and the alternate hypothesis
variance ratio e.
* fct b(a) = qfb(a,10,3/2,e)
* for e = 1:3!10 do draw points(b,.01:.4!100)
* left title "rejection error (beta)"
* bottom title äcceptance error (alpha)"
* top title "beta vs. alpha curves for n1=10, n2=15, e=1:3!10"
* view
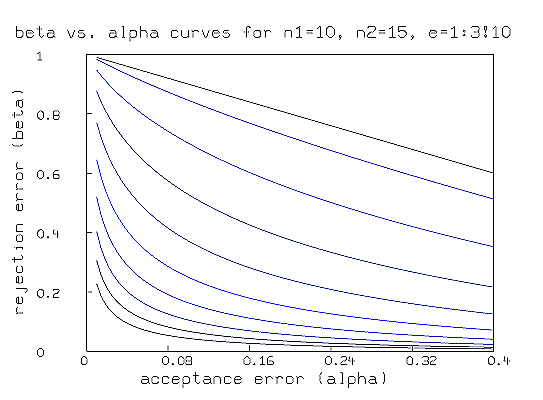
Suppose we want to take n samples from each of two populations to be
used to test whether these populations have the variance ratio 1
versus the variance ratio e, with acceptance error probability
a = .05 and rejection error b = .05. We can use the
builtin function /QFN/ to compute the sample size n as a function
of e as follows. The function /QFN/(a,b,q,e)
returns the sample size n that corresponds to the variance ratio
numerator sample size, assuming the denominator sample size qn, and given that the acceptance error probability is a, the
rejection error probability is b, and the alternate hypothesis
variance ratio value is e.
* fct n(e) = qfn(.05,.05,1,e)
* draw points(n,.1:2.5!50)
* top title ßample size vs. variance ratio (with a=b=.05,t=1)"
* left title ßample size (n)"
* bottom title "variance ratio (e)"
* view
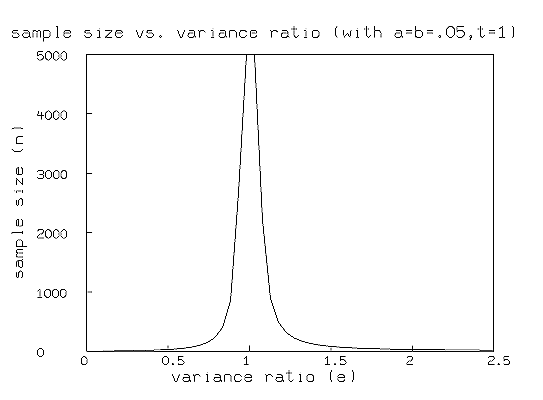
|